KEDA: Autoscale Kubernetes Workloads the Way You Want
Autoscaling in Kubernetes
Before getting into KEDA, let’s get a brief of autoscaling in Kubernetes in general. If your application workloads start receiving more traffic then there is a need to scale up resources to meet the certain demand and scale down while the traffic is low. Note: In this article we will only discuss autoscaling in Kubernetes with respect to workloads but not cluster autoscaler which will add more compute resources to the cluster to accommodate all the workloads. More about cluster autoscaler here. When we talk about autoscaling of workloads in Kubernetes we have two components:
Horizontal Pod Autoscaler (HPA)
HPA adjusts the number of pods backed by controllers such as deployments and Statefulsets depending upon the certain metrics. The common metrics are CPU and Memory usage of all the pods of that particular controller.
Vertical Pod Autoscaler (VPA)
In contrast to HPA; VPA allocates more resources i.e., CPU and Memory to existing pods to meet the traffic demand.
What is Kubernetes Event Driven Autoscaling (KEDA)?
As the name reads, KEDA is a lightweight controller which autoscales the Kubernetes workloads responding to certain events. Uses Native Horizontal Pod Autoscaler to feed external metrics coming out of the Kubernetes cluster. It will autoscale native Kubernetes workloads such as Deployments, Statefulsets, Jobs and it can also autoscale Custom Resource Definitions (CRD).
KEDA is a graduated project under CNCF! Authenticates well with managed Kubernetes services like GKE (Workload Identity), EKS (Pod Identity) etc., for retrieving metrics from event sources. Though you can autoscale based on custom metrics with custom metrics adapter implementations of certain Kubernetes service providers; many of these providers, such as AKS and EKS, have stopped developing custom metrics adapters because projects like KEDA serve these use cases and offer more features.
KEDA didn’t reinvent the wheel, it just passes the events from event source to the native Kubernetes horizontal pod autoscaler (HPA). But it takes the burden of authentication to the event sources.
If you are trying to use KEDA with managed Kubernetes services like GKE, EKS, AKS etc., you can leverage their native identity authentication methods like GCP Workload Identity, Azure Workload identity to talk to their services and retrieve metrics from them.
Architecture
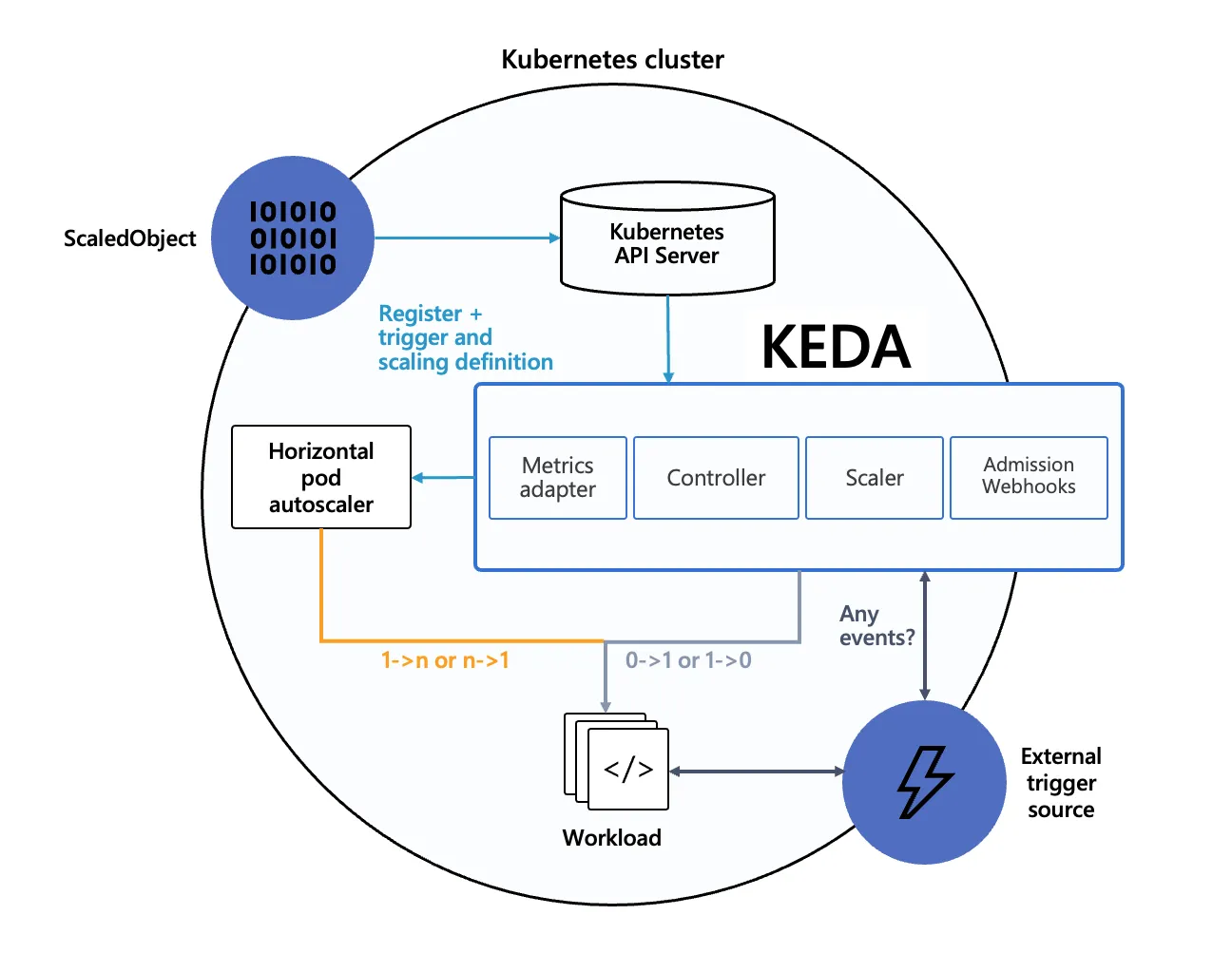
Admission Webhook: To avoid misconfiguration scenarios like multiple HPA for a single targeted resource.
Why KEDA?
- You can scale native Kubernetes workloads such as Deployments and Statefulsets; can scale Kubernetes jobs. It can even scale Custom Resources.
- You don’t need to install multiple custom metric adaptors into your cluster, you can use multiple KEDA scalers that can be used to autoscale your workloads.
What are Scalers?
Scalers define where to get metrics from; or you can say like event sources depending upon which you want to scale your workloads.
We have more than 60+ scalers ranging from different sources:
- Messaging queues such as pub-sub, RabbitMQ, NATS, AWS SQS, Azure Service Bus etc.,
- Monitoring solutions such as GCP Stack driver (Monitoring), AWS CloudWatch, Prometheus, New Relic etc.,
- Databases such as MySQL, MSSQL, PostgreSQL, Redis, AWS DynamoDB etc.,
- Storage solutions such as GCS, Azure Blob storage etc.,
And more..
Components of KEDA
All the components of KEDA are CRD’s that get installed when you install the KEDA setup onto your cluster.
- ScaledObject: Specification that defines how you scale your Deployments and Statefulsets responding to your Events.
- ScaledJob: Specification that defines how you scale your Jobs (run to completion workloads).
- TriggerAuthentication: Specifies the authentication methods to retrieve events from event sources.
- ClusterTriggerAuthentication: Trigger Authentication is limited to a namespace, if you want to refer it across namespaces we can use this resource.
Demo
Let’s try out KEDA using a sample GCP pubsub scaler that scale our workloads responding to unacknowledged messages in the PubSub queue.
Prerequisites
- Access to GCP Project where you can create a GKE cluster and PubSub topic and subscriptions and IAM service account and role binding to the service account
- Client tools gcloud, kubectl, helm installed
Creating a GKE cluster with Workload Identity Enabled:
PROJECT_ID=$(gcloud config get-value project)
gcloud container clusters create keda-demo-cluster --workload-pool=$PROJECT_ID.svc.id.goog --workload-metadata=GKE_METADATA --machine-type=e2-medium --max-nodes=2 --zone=us-central1-a
Make sure workload identity is enabled; we use workload identity to authenticate to the pub-sub resources.
Installing KEDA:
We can deploy KEDA to our cluster using Helm chart
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda - namespace keda - create-namespace
All the components of keda will be deployed to a keda namespace.
Creating IAM Service Account and bindings:
SERVICE_ACCOUNT_NAME=keda-gcppubsubtest
PROJECT_ID=$(gcloud config get-value project)
SERVICE_ACCOUNT_FULL_NAME=$SERVICE_ACCOUNT_NAME@$PROJECT_ID.iam.gserviceaccount.com
gcloud iam service-accounts create $SERVICE_ACCOUNT_NAME - display-name "KEDA PubSub S"
gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$SERVICE_ACCOUNT_FULL_NAME --role roles/monitoring.viewer
gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$SERVICE_ACCOUNT_FULL_NAME --role roles/pubsub.subscriber
Binding GCP IAM Service Account and k8s service account: We need to authenticate the keda operator to be able to retrieve metrics from Pub-Sub, for this we will be using GKE Workload Identity setup. Wait until the cluster is up and running and run below commands.
gcloud iam service-accounts add-iam-policy-binding $SERVICE_ACCOUNT_FULL_NAME \
--role roles/iam.workloadIdentityUser --member "serviceAccount:$PROJECT_ID.svc.id.goog[keda/keda-operator]"
kubectl annotate serviceaccount keda-operator --namespace keda \
iam.gke.io/gcp-service-account=$SERVICE_ACCOUNT_FULL_NAME
#Access to consume pubsub messages from GKE Workloads
gcloud iam service-accounts add-iam-policy-binding $SERVICE_ACCOUNT_FULL_NAME \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:$PROJECT_ID.svc.id.goog[default/default]"
kubectl annotate serviceaccount default --namespace default \
iam.gke.io/gcp-service-account=$SERVICE_ACCOUNT_FULL_NAME
Creating PubSub topic and subscription:
SUBSCRIPTION_NAME=keda-test-subscription
TOPIC_NAME=keda-test-topic
gcloud pubsub topics create $TOPIC_NAME
gcloud pubsub subscriptions create $SUBSCRIPTION_NAME --topic $TOPIC_NAME
gcloud pubsub subscriptions add-iam-policy-binding $SUBSCRIPTION_NAME \
--member=serviceAccount:$SERVICE_ACCOUNT_FULL_NAME --role=roles/pubsub.subscriber
Let’s deploy a sample deployment that consumes messages from pubsub along keda resources triggerauthentication and scaledobject
raghu_manne@cloudshell:~$ k apply -f https://raw.githubusercontent.com/raghu-manne/keda-blog/main/manifests/deploy.yaml
scaledobject.keda.sh/pubsub-test created
triggerauthentication.keda.sh/pubsub-test created
deployment.apps/consume-pubsub-messages created
raghu_manne@cloudshell:~$ kubectl set env deployment consume-pubsub-messages PROJECT_ID=YOUR-ACTUAL-GCP-PROJECT-ID
#Note: Set your actual GCP Project ID in the above command
Let’s see the deployment
raghu_manne@cloudshell:~$ k get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
consume-pubsub-messages 0/0 0 0 67s
If you see the deployment, the replicas are zero despite we mentioned the replica count as 1. Reason being the KEDA scales down the pod count to zero if there are no messages to be consumed in the pub sub queue.
raghu_manne@cloudshell:~$ k describe scaledobjects.keda.sh pubsub-test
Name: pubsub-test
Namespace: default
Labels: scaledobject.keda.sh/name=pubsub-test
…
Events:
Type Reason Age From Message
- - - - - - - - - - - - -
Normal KEDAScalersStarted 4m34s keda-operator Scaler gcp-pubsub is built.
Normal KEDAScalersStarted 4m34s keda-operator Started scalers watch
Normal ScaledObjectReady 4m34s keda-operator ScaledObject is ready for scaling
Normal KEDAScaleTargetDeactivated 4m34s keda-operator Deactivated apps/v1.Deployment default/consume-pubsub-messages from 1 to 0
We will now publish some messages to the pub-sub.
raghu_manne@cloudshell:~ $ TOPIC_NAME=keda-test-topic
raghu_manne@cloudshell:~ $ for x in {1..20}; do gcloud beta pubsub topics publish $TOPIC_NAME --message "Test Message ${x}"; done
messageIds:
- '10436458032317676'
messageIds:
- '10437016284640303'
messageIds:
- '10436245226109532'
messageIds:
- '10436726361647818'
messageIds:
- '10438699104065498'
messageIds:
- '10435599104878680'
messageIds:
- '10437114777032952'
messageIds:
- '10437054531865816'
.
.
.
When we start publishing messages to the pub-sub queue, keda will notice that there are unacknowledged messages in the queue and will pass the same information to the HPA to scale the workloads. If you observe the architecture of KEDA scaling down to zero replicas and to one is the responsibility of the KEDA operator. After one replica the HPA will take over, because HPA doesn’t have capability to scale down to zero.
raghu_manne@cloudshell:~$ k describe scaledobjects.keda.sh pubsub-test
Name: pubsub-test
Namespace: default
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal KEDAScaleTargetActivated 22m keda-operator Scaled apps/v1.Deployment default/consume-pubsub-messages from 0 to 1
HPA now will scale up the replicas to consume all the messages in the queue.

Once there are no messages left in the queue then HPA will eventually scale down the replicas.

And then ScaledObject kicks in and scales down the remaining one pod to zero.
All the commands and scripts used can be found here.